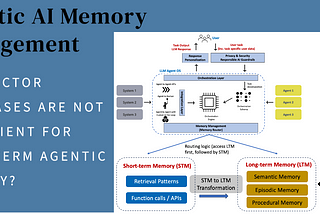
InAI AdvancesbyDebmalya BiswasLong-term Memory for AI AgentsWhy Vector Databases are not sufficient for Memory Management of Agentic AI Systems?Dec 8, 202420Dec 8, 202420
InAI AdvancesbyIsuru Lakshan EkanayakaDeploying and Managing Ollama Models on Kubernetes: A Comprehensive GuideDeploying machine learning models can be challenging, especially when aiming for scalable and maintainable deployments. Kubernetes (K8s)…Nov 9, 2024Nov 9, 2024
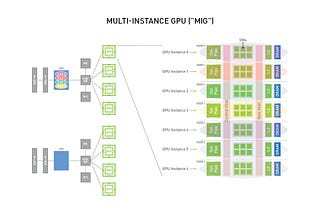
InvmacwritesbyVidyasagar MachupalliNvidia MIG with GPU Optimization in KubernetesMulti-Instance GPU (MIG) is a technology that allows partitioning of a single GPU into multiple smaller, isolated GPU instances. This…Dec 7, 2024Dec 7, 2024
InLevel Up CodingbyWeining MaiFinetune Llama3.2:1b for free with Unsloth and use in Ollama locallyA few months ago, when I needed to finetune a multi-modal model, I had to rent an Nvidia GPU from Runpod and setup a virtual environment…Nov 15, 2024Nov 15, 2024
InTDS ArchivebyTula MastermanIntroducing Layer Enhanced Classification (LEC)A novel approach for lightweight safety classification using pruned language modelsDec 20, 20243Dec 20, 20243
InGoPenAIbykirouane AyoubServing Large models (part two): Ollama and TGIIn the first part of our “Serving Large Models” series, we explored powerful tools like VLLM, LLAMA CPP Server, and SGLang, each offering…Aug 19, 2024Aug 19, 2024
InArtificial Intelligence in Plain EnglishbySreedevi GogusettyFrom RAG to TAG: Leveraging the Power of Table-Augmented Generation (TAG): A Leap Beyond…As artificial intelligence (AI) continues to evolve, so do the methods it uses to interact with and leverage data. Two significant…Dec 6, 20248Dec 6, 20248
InTDS ArchivebyThomas ReidBoost Your Python Code with CUDATarget your GPU easily with Numba’s CUDA JITNov 20, 20242Nov 20, 20242
InTDS ArchivebyNikola Milosevic (Data Warrior)How to Easily Deploy a Local Generative Search Engine Using VerifAIAn open-source initiative to help you deploy generative search based on your local files and self-hosted (Mistral, Llama 3.x) or commercial…Nov 21, 20243Nov 21, 20243
InTDS ArchivebyEric BrodaAgentic Mesh — Principles for an Autonomous Agent EcosystemFoundational principles that let autonomous agents find each other, collaborate, interact, and transact in a growing Agentic Mesh…Nov 19, 20241Nov 19, 20241
InTDS ArchivebyMaxime JabarianFrom Local to Cloud: Estimating GPU Resources for Open-Source LLMsEstimating GPU memory for deploying the latest open-source LLMsNov 18, 20241Nov 18, 20241
InDev GeniusbyTim Urista | Senior Cloud EngineerImplementing AgentOps for Observability in Foundation Model-Based AgentsAs the capabilities of Large Language Models (LLMs) continue to advance, the development of foundation model-based autonomous agents has…Nov 15, 2024Nov 15, 2024
InTDS ArchivebyEric SilbersteinTracing the Transformer in DiagramsWhat exactly do you put in, what exactly do you get out, and how do you generate text with it?Nov 7, 20247Nov 7, 20247
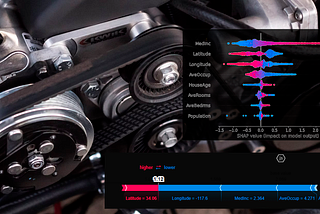
InTDS ArchivebyVinícius TrevisanUsing SHAP Values to Explain How Your Machine Learning Model WorksLearn to use a tool that shows how each feature affects every prediction of the modelJan 17, 20227Jan 17, 20227
Don LimWhat is 1-bit LLM? — Bitnet.cpp may eliminate GPUsMicrosoft introduces Bitnet.cpp, a lightweight AI model that can run efficiently on a portable device.Oct 19, 20244Oct 19, 20244
InTDS ArchivebyMuhammad ArdiPaper Walkthrough: Attention Is All You NeedThe complete guide to implementing a Transformer from scratchNov 3, 202412Nov 3, 202412
InLevel Up CodingbyMd Monsur aliMeta LayerSkip Llama3.2 1B: Achieving Fast LLM Inference with Self-Speculative Decoding locallyA Comprehensive Guide to LayerSkip Technology, Its Advantages, Evaluation, and Practical Meta LayerSkip Tutorial in Local MachineOct 31, 20242Oct 31, 20242
InTDS ArchivebyAlex PunnenLeveraging Smaller LLMs for Enhanced Retrieval-Augmented Generation (RAG)Llama-3.2–1 B-Instruct and LanceDBOct 18, 20246Oct 18, 20246
InTDS ArchivebyThuwarakesh MurallieI Fine-Tuned the Tiny Llama 3.2 1B to Replace GPT-4oIs the fine-tuning effort worth more than few-shot prompting?Oct 15, 202429Oct 15, 202429
InTDS ArchivebyThuwarakesh MurallieHow Much Stress Can Your Server Handle When Self-Hosting LLMs?Do you need more GPUs or a modern GPU? How do you make infrastructure decisions?Oct 19, 20245Oct 19, 20245